
Intro
Discover 5 ways to filter duplicates, removing duplicate data, and duplicate records with data filtering techniques, duplicate detection, and data cleansing methods for accurate results.
The importance of data quality cannot be overstated, especially in today's digital age where information is power. One of the common issues that plague datasets is the presence of duplicate entries, which can lead to inaccurate analysis, wasted resources, and poor decision-making. Removing duplicates is a crucial step in data preprocessing, and there are several ways to do it. In this article, we will explore five ways to filter duplicates, helping you to improve the integrity of your data and make informed decisions.
Data duplication can occur due to various reasons such as human error, data entry mistakes, or the merging of datasets. Whatever the reason, it is essential to identify and remove duplicates to ensure that your data is reliable and consistent. With the increasing amount of data being generated every day, the need for efficient duplicate removal techniques has never been more pressing. By understanding the different methods available, you can choose the best approach for your specific use case and ensure that your data is duplicate-free.
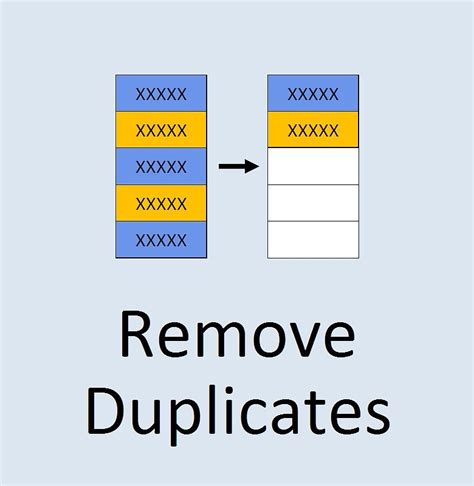
The process of removing duplicates involves identifying unique records and eliminating any redundant entries. This can be a challenging task, especially when dealing with large datasets. However, with the right techniques and tools, you can simplify the process and achieve accurate results. From manual methods to automated solutions, there are various ways to filter duplicates, each with its strengths and weaknesses. By exploring these different approaches, you can develop a comprehensive understanding of how to tackle duplicate data and improve the overall quality of your information.
Understanding Duplicates

Method 1: Manual Removal

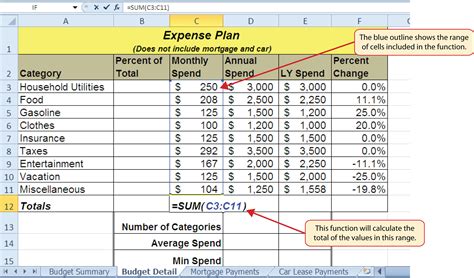
Method 2: Using Spreadsheet Functions
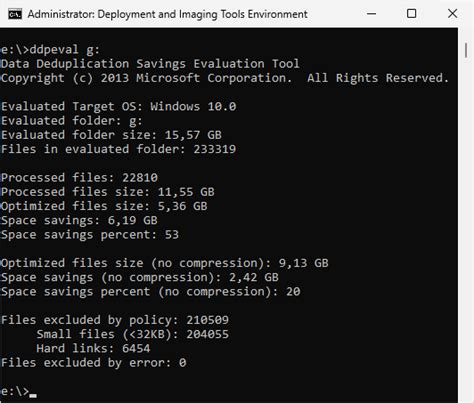
Method 3: Data Deduplication Tools
Method 4: SQL Queries

Method 5: Machine Learning Algorithms
Benefits of Removing Duplicates
Removing duplicates from your dataset offers several benefits, including improved data quality, reduced storage costs, and enhanced decision-making. By eliminating duplicate records, you can ensure that your data is accurate, consistent, and reliable, making it easier to analyze and work with. Additionally, removing duplicates can help reduce storage costs, as you will no longer need to store redundant data. Finally, by improving the quality of your data, you can make more informed decisions, driving business success and growth.Best Practices for Removing Duplicates
When removing duplicates from your dataset, it is essential to follow best practices to ensure accuracy and efficiency. These best practices include verifying the accuracy of your data, using automated tools and techniques, and testing your duplicate removal process. By following these best practices, you can ensure that your duplicate removal process is effective, efficient, and reliable, producing high-quality data that drives business success.Duplicate Removal Image Gallery





What is data deduplication?
+Data deduplication is the process of removing duplicate copies of data, ensuring that only one copy of each piece of data is stored.
Why is removing duplicates important?
+Removing duplicates is important because it improves data quality, reduces storage costs, and enhances decision-making.
What are the benefits of using machine learning algorithms for duplicate removal?
+The benefits of using machine learning algorithms for duplicate removal include improved accuracy, increased efficiency, and the ability to handle large, complex datasets.
How can I verify the accuracy of my data after removing duplicates?
+You can verify the accuracy of your data after removing duplicates by manually reviewing a sample of the data, using data validation techniques, or comparing the data to other sources.
What are some best practices for removing duplicates from my dataset?
+Some best practices for removing duplicates from your dataset include verifying the accuracy of your data, using automated tools and techniques, and testing your duplicate removal process.
In conclusion, removing duplicates from your dataset is a crucial step in ensuring data quality and driving business success. By understanding the different methods available, including manual removal, using spreadsheet functions, data deduplication tools, SQL queries, and machine learning algorithms, you can choose the best approach for your specific use case. Remember to follow best practices, such as verifying the accuracy of your data and testing your duplicate removal process, to ensure that your data is accurate, consistent, and reliable. By taking the time to remove duplicates from your dataset, you can improve decision-making, reduce costs, and drive business growth. We invite you to share your thoughts on duplicate removal and data quality in the comments below, and to share this article with others who may benefit from learning about the importance of removing duplicates from their datasets.